1. Basic
Spring Cloud是一套组件,包含服务发现,配置中心,消息总线,负载均衡,断路器和数据监控等。
- 服务治理和服务发现:主要使用的是Netflix Eureka。Spring Cloud对其进行封装后使得开发者可以使用Spring Boot的风格使用它。通过服务注册将单个microserivce注册给服务治理中心,这样服务治理中心就可以治理单个微服务节点。服务发现则是微服务节点可以对服务治理中心发送消息,使得服务治理中心可以将新的微服务节点纳入管理。
- 客户端负载均衡:每一个microservice都会存在多个节点,当一个service(service consumer)调用另一个service(service producer)时,service producer需要通过load balancer算法提供一个节点进行响应。另外,通过负载均衡也可以将故障节点排除。Spring Cloud使用Ribben来实现它。
- 声明服务调用:Spring Cloud提供了接口式的声明服务调用编程,它就是Feign。通过它请求其他微服务时,就如同调度本地服务的Java接口一样,从而再多次调用的情况下简化开发者的编程,同时提高编码的可读性。
- 断路器:当服务提供者响应延迟或者故障时,就会使得服务消费者长期得不到响应,Hystrix就会对这些延迟或者故障的服务进行处理。
- API Gateway:Spring Cloud中的API Gateway是Zuul。第一个作用是将请求的地址映射为真实服务器地址,起到路由分发的作用,降低单个节点的请求,实现服务器负载均衡。第二个作用是过滤服务,通过过滤器过滤那些恶意或者无效的请求,把它们排除在网站之外,降低服务的风险。
Eureka - 服务治理和发现
- 通过
@EnableEurekaServer来开启Eureka Service。(和SpringBoot Application的启动方法一致)。 以下几个config在Eureka中非常重要:
eureka.client.serviceUrl.defaultZone:代表服务中心的域,将来可以提供给别的microservice进行注册。-
eureka.client.register-with-eureka:默认情况下为true,项目会自动查找Eureka的server去注册。Server本身则不需要,设为false。
- 新的Spring Cloud版本只要在pom中有依赖eureka-client,便会默认使用
@EnableDiscoveryClient,因此不需要再显示的使用此Annotation。 - 如果要开启同一个服务的多个instance,必须保证配置中的
spring.application.name相同,因为Eureka Server是通过microservice的名字来判断是否是新的节点的。 - 通过对于eureka server的互相注册(
eureka.client.serviceUrl.defaultZone),可以实现多个服务治理中心。同时通过在client端添加多个服务治理中心,可以实现多个client节点注册多个服务治理中心。
Ribbon & Feign - 微服务之间的调用
Ribbon
- 通过使用Ribbon以及其默认的负载均衡算法,就可以在各个微服务互相调用的过程中自动实现负载均衡。
- 只需要引入Ribbon包和一个简单的
@LoadBalance注解(初始化RestTemplate时)就可以使用负载均衡算法,降低单个endpoint的压力。 - 通过在RestTemplate的URL中使用在Eureka中注册的Service ID,便可以不需要定义服务器和port然后让Ribbon来调用负载均衡。
Feign
- 不同于Ribbon,Feign屏蔽了RestTemplate的使用,而是使用接口式的声明调用,相比Ribbon,Feign显得更简洁,更容易让人理解,同时在多次调用时更加方便。
- Feign也是通过使用在服务治理中心的Service ID来找到对应的微服务并且实现负载均衡的。
Hystrix - 断路器
- 在分布式系统中,如果一个服务不可用,而其他微服务还大量的调用这个不可用的微服务,也会导致其自身不可用,其自身不可用之后又可能蔓延到其他与之相关的微服务上,这样就会导致更多的微服务不可用,最后导致分布式服务瘫痪。
- 为了解决上面的情况,Hystrix出现了,在微服务系统之间大量调用可能导致service consumer自身出现瘫痪的情况下,Hystrix就会将这些积压的大量请求熔断,来保证其自身服务可用,而不会蔓延到其他的微服务上去。通过这样的熔断机制可以保持各个微服务持续可用。
- 通常来说,处理限制请求的方式的策略有很多,比如限流,缓存之类。最常用的是降级服务。
- 降级服务就是当请求其他微服务出现超时或者发生故障时,就会使用自身服务其他的方法进行响应。
- Hystrix的默认监控微服务的超时时间为2s。
- 通过启用Spring Actuator和hystrix.stream,可以通过Hystrix Dashboard来对断路器的服务进行监控。
Zuul - 路由网关
- 网关的功能对于分布式微服务是十分重要的,首先它可以将请求路由转发到真实的服务器上,进而保护服务器真实的IP地址,避免直接地攻击真实服务器;其次它可以作为一种load balancer的手段,使得request可以按照算法平摊到多个endpoint上;最后它还能提供filter,可以判断request是否为有效请求,一旦判定失败,就可以将请求阻止,避免发送到真实的服务器,降低服务器的压力。
- Zuul的注解中自动引入了断路机制,可以避免请求不到的时候进行断路,避免网关发生请求无法释放的场景导致微服务瘫痪。
Filter
- 通过继承ZuulFilter便可以实现对于请求的过滤和拦截。需要重写四个方法。
shouldFilter:返回boolean值,如果为true则执行过滤器的run方法。run:运行过滤逻辑,过滤器的核心方法。filterType:过滤器类型,通过返回一个字符串来配置过滤器运行时机。- pre:请求执行之前filter
- route:处理请求,进行路由,filter
- post:请求处理完成后执行filter
- error:出现错误时执行filter
filterOrder:指定过滤器顺序,值越小越优先。
@SprngCloudApplication
- 通过使用
@SpringCloudApplication,整合了以下三个Annotation@SpringBootApplication@EnableDiscoverClient@EnableCircuitBreaker
2. MicroServices
Monolith System
- 传统的Monolith System已经很难满足互联网技术的发展要求(在系统开发的初期Monolith仍然有着显著的优势)。主要体现在两方面:
- 业务复杂度的提高导致代码的可维护性,scalability和readability降低。新人接手代码的时间成倍增加。
- 维护系统成本,修改系统的成本变高。
- 测试难度变大,修改业务或者增加业务可能引起对于应用测试的连锁反应。
- 采用Monolith System + Cluster的缺陷:
- Single Application,代码的可维护性,scalability和readability依然很差。
- 数据库将成为瓶颈,解决方案需要使用分布式数据库,也就是将数据库进行分库分表。
- 持续交付能力交差,每一次小的改动都需要对整个项目进行编译和部署,非常耗时。
MicroServices
- 什么是MicroSevices:
- 按业务划分为一个独立service component
- 通过微服务,服务与服务之间没有任何的coupling,有非常好的scabbily和reusability。
- Loose coupling implies that services are independent so that changes in one service will not affect any other. The more dependencies you have between services, the more likely it is that changes will have wider, unpredictable consequences.
- 通过HTTP来进行通信,通常使用JSON/XML
- 通过HTTP通信存在着一个显著的弊端,程序的响应速度受限于网络条件,并且该机制不是特别可靠,总会有失败的网络通信。
- CICD
- 通过CICD,提高了部署的效率,减少了人为的控制,使得部署自动化,提高了软件质量。
- 可以使用不同的programming language
- 服务集中化管理
- Distributed System
- 分布式系统通过网络协议来通信,所以分布式系统在空间上没有任何的限制,即分布式可以部署在不同机房和不同的地区。
- 数据库独立
- 随着业务的扩张,服务与服务之间不需要提供数据库集成,而是提供API相互调用。
- 单业务的数据量少,易于维护,数据库性能有着显著优势,并且数据库迁移也比较方便。
- 易于对数据进行读写分离。
- 按业务划分为一个独立service component
- MicroServices通常通过三个条件来划分:
- Lines of Code
- Develop Length
- 业务大小
- 微服务的熔断机制,有着对于不可用的节点进行自熔断和自我修复的机制。这种自我熔断机制和自我修复的机制在微服务架构中有着重要的意义,一方面,它使程序更加健壮,另一个方面,为开发和维护减少很多不必要的条件。
- Advantage of MicroServices
- 服务的边界明确,将复杂的问题简单化。
- 代码的readability和scalability变高。
- 服务与服务之间没有coupling,具有极强的横向扩展能力。
- 可以集群化部署,从而增加系统的负载能力。
- 可以采用根据不同的需求采用任何开发语言和技术来实现。提高开发效率,降低开发成本。
- 重写简单。
- 减少了测试和部署的时间,只需要进行对改动代码的测试,只要接口没有修改就不需要进行大面积的功能测试。
- 然而MicroServices也有着一些不足之处
- 系统的复杂度增加
- 微服务构建的复杂度远远超过Monolith,要考虑服务与服务之间通信的最佳机制,并且要考虑网络服务较差时带来的风险。
- 分布式事务(Transaction)
- 对于CAP理论的实践(在分布式系统中,P是基本要求,而Monolith则是CA系统)
- Consistency: 数据的强一致性
- Availability: 服务的可用性
- Partition-tolerance: 分区容错
- 由于分布式事务会阻塞线程,降低数据库性能,因此尽量少用分布式事务。
- 对于CAP理论的实践(在分布式系统中,P是基本要求,而Monolith则是CA系统)
- 微服务的划分
- 通过Domain Driven Design,是一个比较理想的微服务拆分的理念。通过分析代码和数据,找到切分点,通过数据分析来判断服务的边界和划分粒度。
- 微服务的部署
- Docker是微服务最佳部署的容器。
- 系统的复杂度增加
- 分布式事务一般的解决办法就是两阶段提交或者三阶段提交,如果存在事务失败导致数据不一致,则关键时刻还得人工进行恢复。微服务的设计一定是渐进式的,并且是随着业务发展而发展的。
3. Spring Cloud
- 对于一个微服务系统,通常都需要以下组件
- 服务的发现和注册
- 通常一个服务实例注册后,会定时向服务注册中心提供心跳,以表明自己还处于可用的状态。当一个服务实例停止向服务注册中心提供心跳一段时间后,服务注册中心会认为该服务实例不可用,会将该服务实例从服务注册中心列表中移除。如果这个被移除的实例过一段时间后继续向注册中心提供心跳,那么服务注册中心会将该服务实例重新加入服务注册中心的列表中。
- 一般服务注册中心也会实现多个Cluster。
- Load Balancer
- 服务消费者通常集成负载均衡组件,该组件会向服务消费者获取服务注册列表信息,并每隔一段时间重新刷新该列表。当服务消费者消费服务时,负载均衡组件提供服务提供者所有实例的注册信息,并通过一定的负载均衡策略,选择一个服务提供者的实例进行消费。
- Circuit Breaker
- 提供服务降级,服务限流和自我修复的能力。
- API Gateway
- 服务分发,安全认证,流量监控。
- Config Management
- Tracing Analysis
- 用来分析各个微服务之间的依赖关系和对异常或者错误进行快速定位。
- Log
- 服务的发现和注册
Spring Cloud
- Eureka - 服务注册和发现组件
- Hystrix - 熔断器
- Ribbon(和RestTemplate配合使用或者使用Feign-继承了Ribbon) - 负载均衡
- Zuul - API网关
- Spring Cloud Config - 配置中心, Spring Cloud Bus - 消息总线组件。两者常用来用于动态刷新服务的配置。
- Spring Cloud Security - 安全验证
- Spring Cloud Sleuth - Tracing Analysis
- Spring Cloud Stream - 数据流操作包,对Message Queue进行封装。
Kubernetes
- Kubernetes更偏向于DevOps的概念,提供的许多功能和Spring Cloud有重合的地方,然而Kubernetes更偏向于对于容器的集群化管理,而且是跨平台的。Spring Cloud则是JVM上最好的微服务管理框架。
4. Eureka
Eureka architecture: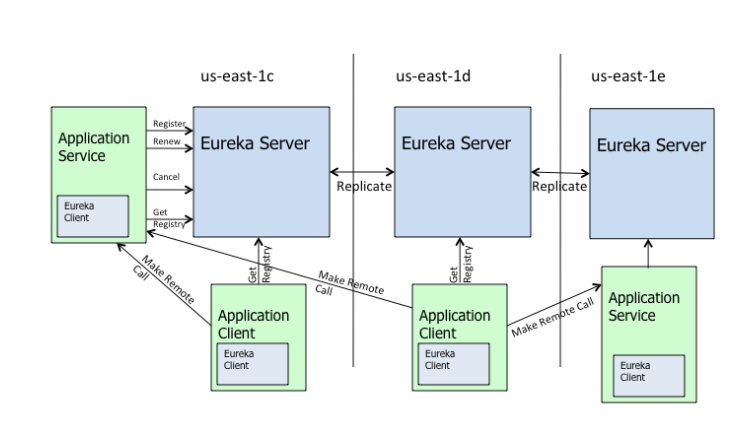
- Eureka的基本架构包含三种角色:
- Register Service - 服务注册中心,它是一个Eureka Server,提供服务注册和发现的功能。
- 服务注册列表信息和服务续约信息都会被复制到Cluster中的每一个Eureka Server节点。
- Provider Service - 服务提供者,它是一个Eureka Client,提供服务,
- Consumer Service - 服务消费者,它是一个Eureka Client,消费服务。
- Register Service - 服务注册中心,它是一个Eureka Server,提供服务注册和发现的功能。
Register - 服务注册
- 当Eureka Client向Eureka Server注册时,Eureka Client提供自身的metadata,比如IP,Port,URL和host信息。
- 如果Eureka Client在配置文件中没有配置ServiceId,则默认为配置文件中的配置服务名-
spring.application.name的值。 - 当Eureka Client启动时,会将自身的服务信息发送到Eureka Server。
Renew - 服务续约
- Eureka Client在默认情况下会每隔30s发送一次heartbeat来进行服务Renew。通过Renew来告知Eureka Server该Eureka Client仍然可用,无故障。正常情况下,如果Eureka Server在90s内没有收到Eureka Client的心跳,Eureka Server将会在Eureka Client实例从注册列表中移除。不建议更改Renew的间隔时间。
Fetch Registries - 获取服务注册列表信息
- Eureka Client从Eureka Server获取服务注册表的信息,并将其缓存在本地。Eureka Client会使用服务注册表信息查找其他服务的信息,从而进行调用。该注册表信息30s更新一次。如果遇到某些故障无法更新注册表信息,Eureka Client会重新获取整个注册表的信息。默认情况下Eureka Client使用JSON格式的方式来获取服务注册列表信息。
- 在一个集群中,来自任何区域的Eureka Client都可以获取整个系统的服务注册列表信息。
- 为什么有时候Eureka Client获取服务实例不是很及时?
- Eureka Client注册延迟
- Eureka Client启动之后,不是立即向Eureka Server注册的,默认的延迟时间为40s。
- Eureka Server的响应缓存
- Eureka Server每30s更新一次响应缓存,所以即使是刚刚注册的实例,也不会立即出现在服务注册列表中。
- Eureka Client的缓存
- Eureka Client保留注册表信息的缓存,30s刷新一次,Eureka Client刷新本地缓存并发现其他新注册的实例可能需要30s。
- LoadBalancer的缓存
- Ribbon的负载平衡器从本地的Eureka Client获取服务注册列表信息,并且缓存起来,以避免每个请求都需要从Eureka Client获取服务注册列表。此缓存30s刷新一次。
- Eureka Client注册延迟
Cancel - 服务下线
- Eureka Client在程序关闭时可以向Eureka Server发送下线请求。发送请求后,该客户端的实例信息将从Eureka Server的服务注册列表中删除。该下线请求不会自动完成,需要在程序关闭时调用代码:
DiscoveryManager.getInstance().shutdownComponent();
Eviction - 服务剔除
- 在默认情况下,当Eureka Client连续90s没有向Eureka Server发送服务续约时,Eureka Server会将该服务的实例从服务注册列表中删除。
Eureka的自我保护模式
- 在任何时间,如果Eureka Server接收到的服务Renew低于该值配置的百分比(默认为15min内低于85%),则服务器开启自我保护模式,不再剔除注册列表的任何信息。这样做的好处在于,如果是Eureka Server自身的网络问题而导致Eureka Client无法续约,Eureka Client的注册列表信息不再被删除,也就是Eureka Client还可以被其他服务消费。
5. Ribbon
Overview
- Ribbon的负载均衡主要是通过LoadBalancerClient来实现的,而LoadBalancerClient具体交给了ILoadBalancer来处理,ILoadBalancer通过配置IRule,IPing等,向EurekaClient获取注册列表的信息,默认每10秒向注册列表中所有的服务发送一次Ping(默认的IPing方法是通过从EurekaClient中获取的注册列表的服务Status来判断是否可用的),进而检查是否需要更新LoadBalancerClient中的服务的注册列表信息(从EurekaClient中更新)。最后,在得到服务注册列表信息后,ILoadBalancer根据IRule的策略进行负载均衡。
- RestTemplate负载均衡的实现是通过在RestTemplate中添加了一个LoadBalancerInterceptor,在Interceptor中调用了LoadBalancerClient的负载均衡算法,使得RestTemplate会去对应的微服务上获取资源。
- Ribbon作为Service Consumer的负载均衡器,有两种使用方式
- 使用RestTemplate
- 使用Feign - 默认集成了Ribbon
LoadBalancerClient
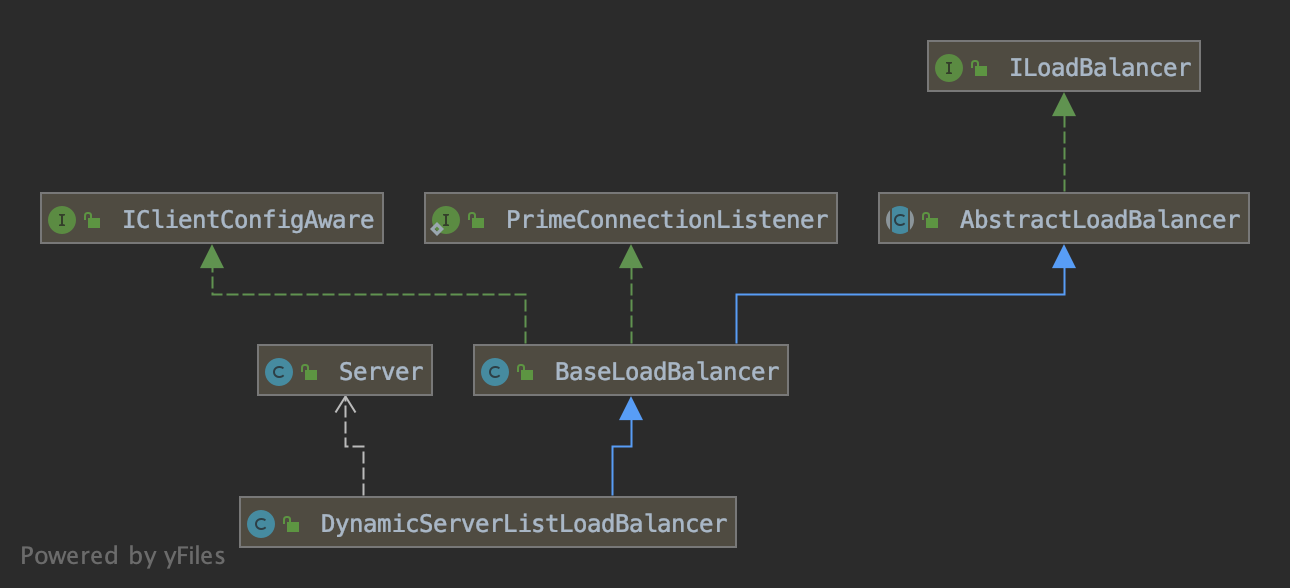
- 负载均衡类的核心类是LoadBalancerClient,LoadBalacnerClient可以获取负载均衡类的服务提供者的实例信息。负载均衡器LoadBalancerClient是从Eureka Client获取服务注册列表信息的,并将服务注册列表信息进行缓存,然后通过调用
choose()方法来选择一个服务实例。LoadBalancerClient也可以不从Eureka Client获取注册列表信息,这时需要自己维护一份服务注册列表信息。 - ILoadBalancer的实现类DynamicServerListLoadBalancer是实现找到对应的服务实例和维护注册服务列表的类。
- IRule是实现负载均衡算法的类,有很多的IRule,根据不同的算法和逻辑来处理不同的负载均衡策略。默认有7种实现类。
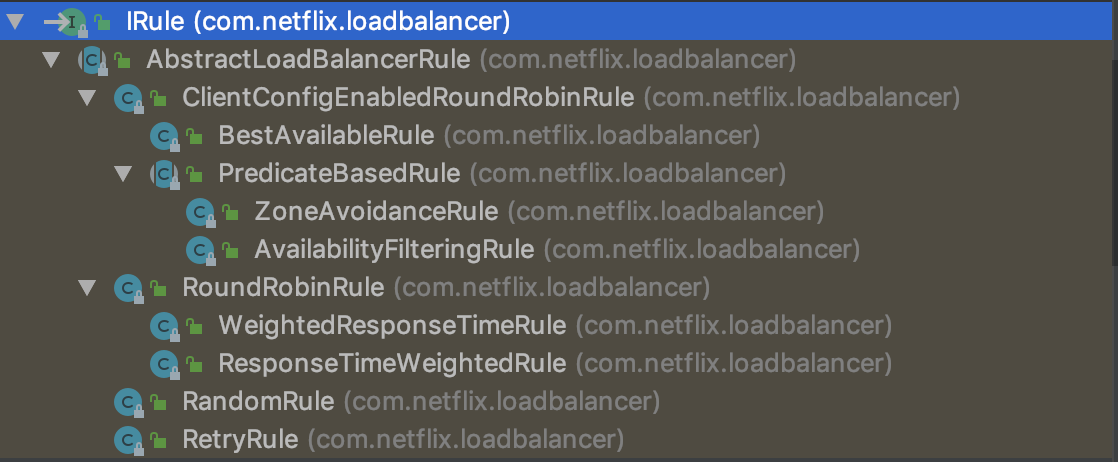
- BestAvailableRule:选择请求数最小的server。
- ClientConfigEnabledRoundRobinRule:轮询。
- RandomRule:随机选择一个server。
- RoundRobinRule:轮询选择server。
- RetryRule:根据轮询的方式进行retry。
- WeightedResponseTimeRule:根据响应时间去分配一个weight,weight越低,被选择的可能性就越低。
- ZoneAvoidanceRule:根据server的zone区域和可用性来轮询。
- AvailabilityFilteringRule
- IPing用于向注册列表中的所有服务发送ping,来判断该server是否有响应,从而判断该server是否可用。IPing的策略如下:
- PingUrl:真实地去ping某个服务,判断其是否可用。
- PingConstant:固定返回某服务是否可用,默认返回true,即可用。
- NoOpPing:不去ping,直接返回true,即可用。
- DummyPing:直接返回true,并实现了
initWithNiwsConfig方法。 - NIWSDiscoveryPing(默认的IPing方法):根据DisvoveryEnabledServer的InstanceInfo的InstanceStatus去判断,如果InstanceStatus为UP,则可用,否则不可用。
- LoadBalancerClient是在初始化时向Eureka获取服务注册列表信息,并且每隔十秒向EurekaClient发送ping,来判断服务的可用性。如果服务的可用性发生了改变或者服务数量和之前的不一致,则更新或者重新拉取。在默认情况下使用的IPing方法返回值一直保持为服务可用(always return true because status is UP!)直到30s后Ribbon对缓存进行刷新。
6. Feign
- 在Feign的pom.xml中可以看出Feign默认起步依赖引入了Ribbon和Hystrix的依赖。
FeignClient
- @FeignClient注解可以用于创建声明式API接口,该接口是典型的Restful风格的。Feign被设计成插拔式的,可以注入其他组件和Feign一起使用。最典型的是如果Ribbon可用,Feign会和Ribbon相结合进行负载均衡。
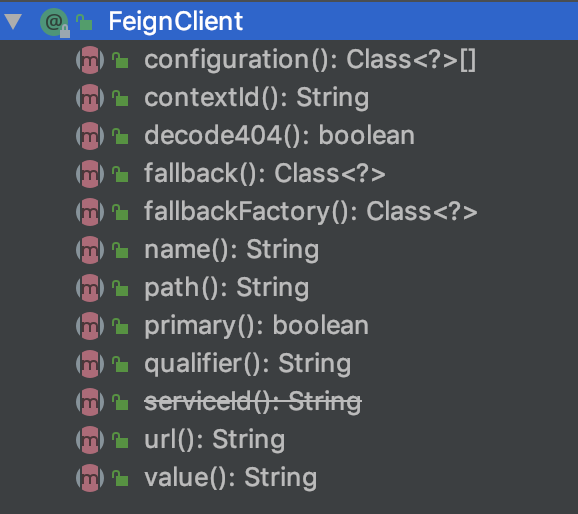
value()和name()是一样的,是被调用的服务的ServiceId。url()是直接填写硬编码的URL地址。decode404()即404是被解码,还是直接抛出异常。configuration()指明FeignClient的配置类,默认为FeignClientsConfiguration,这个类默认注入了Decoder,Encoder和Contract等配置的Bean。fallback()为配置熔断器的处理类。
- FeignClientsConfiguration这个类注入了很多Feign相关的配置Bean,包括FeignRetryer, FeignLoggerFacotry和FormattingConversionService。另外Decoder,Encoder和Contract这三个类在没有Bean被注入的情况下,会自动注入默认配置的Bean,即ResponseEntityDecoder,SpringEncoder和SpringMVCContract。
- 注意,只要重写FeignClientsConfiguration类中的Bean,就会覆盖掉默认的配置的Bean,从而达到自定义配置的目的。
Feign的工作原理
- Feign是一个伪Java Http client,Feign不做任何的请求处理。Feign通过处理注解生成Request模版的方式,简化了Http API的开发。在发送Http Request请求之前,Feign通过处理注解的方式替换掉Request模版中的参数,生成真正的Request,并交给Java Http client去处理。简单的说就是会根据注解中所提供的参数生成RequestTemplate,然后生成Request对象然后通过Http client进行Http请求并获得响应。
Feign与HttpClient和OkHttp
- 默认情况下Feign使用的FeignClient是Client.Default,是由HttpURLConnection来实现网络请求的。
- 在pom.xml加入feign-httpclient就会使用HttpClient作为网络请求框架。
- 在pom.xml加入feigh-okhttp就会使用Okhttp作为网络请求框架。
Feign与负载均衡
- Feign最终向IOC容器中注入的Client类是LoadBalancerFeignClient,底层是通过Ribbon实现的负载均衡。
Conclusion
- 首先通过@EnableFeignClients注解开启FeignClient的功能。只要这个注解存在,程序启动时就会对@FeignClient类进行扫描。
- 根据Feign规则实现Service接口并使用@FeignClient注解。
- 程序启动时,IOC容器会被注入所有含有@FeignClient的类。
- 当Service接口中的方法被调用时,通过JDK的代理来生成具体的RequestTemplate模版对象。
- 根据RequestTemplate再生成Http请求的Request对象。
- Request对象交给Client处理,其中Client的网络请求框架默认是HttpURLConnection,也可以使用HttpClient或者OkHttp。
- 最后Client被封装成LoadBalanceClient类,这个类结合Ribbon达到了负载平衡。
7. Hystrix
- 在分布式系统中,服务与服务之间的依赖错综复杂,一种不可避免的情况就是某些服务会出现故障,导致依赖于它们的其他服务出现远程调度的线程阻塞。Hystrix是通过隔离服务的访问点阻止联动故障的,并提供了故障的解决方案,从而提高了整个分布式系统的弹性。
Hystrix的设计原则
- 防止单个服务的故障耗尽整个服务的Servlet容器的线程资源。
- 快速失败机制,如果某个服务出现了故障,则调用该服务的请求快速失败,而不是线程Block。
- 提供fallback方案,在请求发生故障时,提供设定好的fallback方法。
- 使用熔断机制,防止故障扩散到其他服务。
- 提供熔断器的监控组件Hystrix Dashboard,可以实时监控熔断器的状态。
Hystrix的工作机制
- 首先,当服务的某个API接口的失败次数在一定时间内小于设定的threshold时,熔断器处于关闭状态,该API接口正常提供服务。
- 当该API接口处理请求的失败次数大于设定的threshold时,Hystrix判定该API接口出现了故障,打开熔断器,这时请求该API接口会执行快速失败的逻辑(fallback方法),不执行业务逻辑,请求的线程不会处于阻塞状态。
- Hystrix判断达到threshold的逻辑:within a timespan of duration
metrics.rollingStats.timeInMilliseconds(default 10000), the percentage of actions resulting in a handled exception exceedserrorThresholdPercentage(default 50), provided also that the number of actions through the circuit in the timespan is at leastrequestVolumeThreshold(default 3)。
- Hystrix判断达到threshold的逻辑:within a timespan of duration
- 处于打开状态的熔断器,一段时间后会处于半打开状态(
hystrix.command.default.circuitBreaker.sleepWindowInMilliseconds=50000),并将一定数量的请求执行正常逻辑,剩余的请求会执行快速失败。若执行正常逻辑的请求失败了,则熔断器继续打开。若成功了,则将熔断器关闭,这样熔断器就具有了自我恢复的能力。 - Important Hystrix configurations:
hystrix.command.default.execution.isolation.strategy=SEMAPHOREhystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=10000hystrix.command.default.fallback.enabled=truehystrix.command.default.circuitBreaker.enabled=truehystrix.command.default.circuitBreaker.requestVolumeThreshold=3hystrix.command.default.circuitBreaker.sleepWindowInMilliseconds=50000hystrix.command.default.circuitBreaker.errorThresholdPercentage=50
Hystrix Dashboard
- 熔断器的状况反映了一个程序的可用性和健壮性,它是一个重要的指标。Hystrix Dashboard是监控Hystrix的熔断器的一个重要组件,提供了数据监控和友好的图形化展示界面。
- 引入Hystrix,Hystrix Dashboard和Actuator便可以使用Hystrix Dashboard。
Turbine聚合监控
- 当服务数量很多时,对于每个服务的熔断监控Hystrix便不太方便,因此为了同时监控多个服务的熔断器的状态,Turbine便出现了。
- Turbine用于聚合多个Hystrix Dashboard,将多个Hystrix Dashboard的组件的数据放在一个页面上展示,进行集中监控。
8. Zuul
- Zuul是微服务系统的网关组件,用于构建Edge Service,致力于动态路由,过滤,监控,弹性伸缩和安全。
Zuul的作用
- Zuul,Ribbon和Eureka相结合,可以实现智能路由和负载均衡的功能,Zuul能够将请求按某种策略分发到集群状态的多个服务实例。
- 网关将所有的服务的API接口统一聚合,并统一对外暴露。外界系统调用API接口实现时,都是由网关对外暴露的API接口,外界系统不需要知道微服务系统中各服务相互调用的复杂性。同时,微服务系统也保护了其内部微服务单元的API接口,防止其被外界直接调用,导致服务的敏感信息对外暴露。
- 网关服务可以做到用户身份认真和权限认证,防止非法请求操作API接口,对服务器起到保护作用。
- 网关可以实现流量监控,实时日志输出,对请求进行记录。
- 网关可以用来实现内部流量控制,在高流量的情况下,对服务进行降级。
- API接口可以从内部服务分离出来,方便测试。
Zuul的原理
- Zuul是通过Servlet来实现的,包含四种过滤器:
- PRE过滤器:它是在请求路由到具体服务之前执行的,这种类型的过滤器可以做安全验证。
- ROUTING过滤器:它用于将请求路由到具体的微服务,默认情况下使用Http Client。
- POST过滤器:它是在请求已被路由到微服务后执行的。一般情况下,用作收集统计信息,指标,以及将响应传输到客户端。
- ERROR过滤器:它是在其他过滤器发生错误时执行的。
- Zuul采取了动态读取,编译和运行这些过滤器。过滤器之间不能相互通信,而是通过RequestContext对象来共享数据,每个请求都会对应一个RequestContext对象,过滤器有如下特性:
- Type:决定过滤器在什么阶段起作用。
- Execution Order:决定过滤器的执行顺序,值越小,越先执行。
- Criteria:Filter执行所需要的条件。
- Action:符合条件时执行的行为。
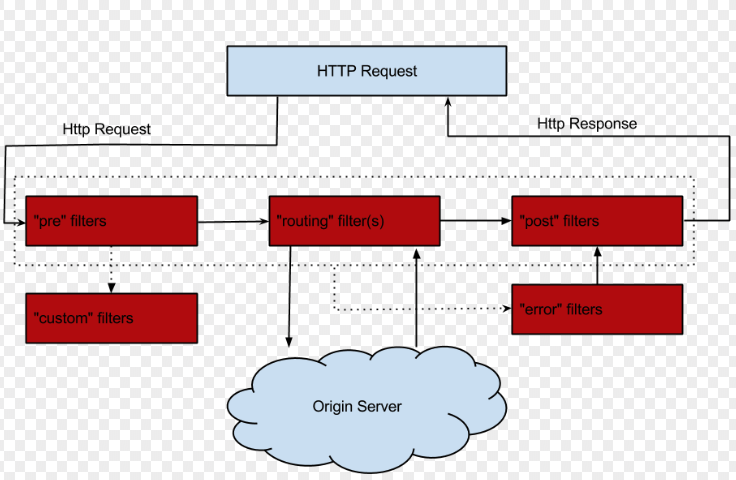
Zuul的Circuit Breaker
- 通过实现
FallbackProvider接口,可以让Zuul包含有熔断的功能(使用Hystrix),该接口有两个方法:getRoute()用于指定熔断功能应用于那些路由的服务,通常返回ServiceId来对某个服务进行熔断,返回*可以对所有的微服务都进行熔断。fallbackResponse()为进入熔断功能时执行的逻辑。
Zuul的Filter
- 通过继承
ZuulFilter并实现其中的抽象方法便可以实现过滤器。 - 如果
setSendZuulResposne方法设置为true, 则将请求分发到具体的服务实例。如果是false,则不分发到具体的微服务实例,默认是true。
Zuul常见的使用方式
- 由于Zuul采用的是IO多路复用模型(selector模型),因此性能不如Ngnix。
- 一种常见的使用方式是对不同的渠道使用不同的Zuul来进行路由,例如移动端,Web端和其他段各一个Zuul的网关实例。
- 另一种方式是通过Ngnix的负载均衡将请求分发至Zuul。
9. Spring Cloud Config
- Config Server可以从本地仓库读取配置文件,也可以从远处Git repo读取配置文件。本地仓库是指所有文件的配置统一写在Config Server工程目录下。Config Server暴露Http API接口,Config Client通过调用Config Server的Http API接口来读取配置文件。
- 一般建议从远程Git repo来读取配置文件,即Config Server可以不从本地的仓库读取,而是从远程Git repo读取。这样做的好处就是将配置统一管理,并且可以通过Spring Cloud Bus在不人工启动程序的情况下对Config Client的配置进行刷新。
构建High Availability的Config Server
- 当服务实例很多时,所有的服务实例需要同时从配置中心Config Server读取配置文件,这时可以考虑将配置中心Config Server做成一个微服务并且集群化,从而达到高可用。通过将多个Config Server和多个Config Client自动注册到Eureka Service Center,便可以自动实现负载均衡(通过Ribbon实现,不需要担心实现细节)。
Spring Cloud Bus
- Spring Cloud Bus是轻量的消息代理将分布式的节点连接起来,可以用于广播配置文件的更改或者服务的监控管理。
- Architecture:
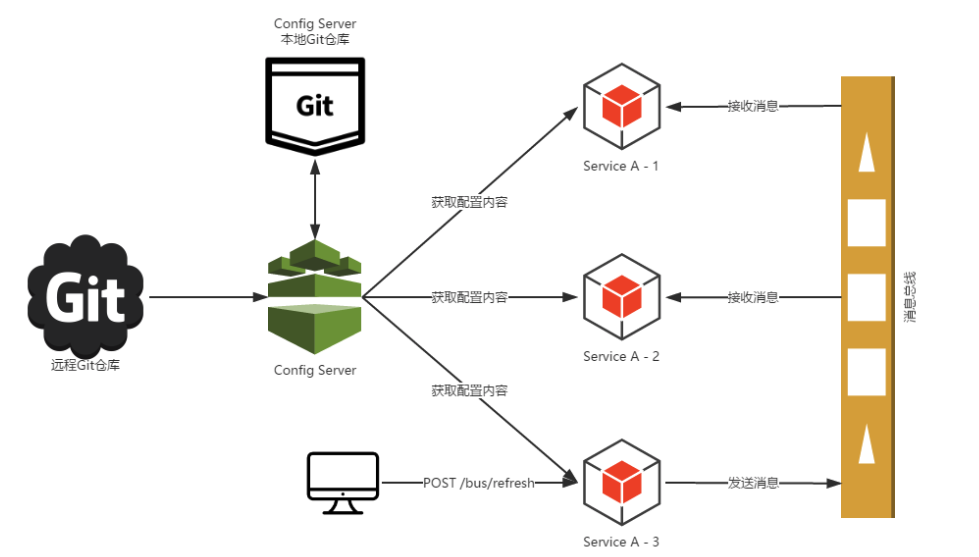
- Spring Cloud Bus的一个功能就是当远程Git repo的配置文件更改后,只需要向某一个微服务实例发送一个Post请求,通过消息组件通知其他微服务实例重新拉取最新的配置文件,不必对所有的微服务实例进行一个一个的更新。
- 在Spring Boot 2.X版本中,URL已经集成到actuator中 -
/actuator/bus-refresh - 也可以使用destination参数来指定对于某一种服务的instance进行刷新 -
/bus-refresh?destination=eureka-client: **。
- 在Spring Boot 2.X版本中,URL已经集成到actuator中 -
10. Spring Cloud Sleuth
- 由于服务单元数量众多,业务的复杂性较高,如果出现了错误和异常,很难去定位。主要体现在一个请求可能需要调用很多个服务,而内部服务的调用复杂性决定了问题难以定位。所以在微服务框架中,必须实现分布式链路追踪,去跟进一个请求到底有哪些服务的参与,参与的顺序又是怎么样的,从而达到每个请求的步骤都清晰可见,出了问题能够快速定位的目的。
Tracing Analysis Terminology
- Span:基本的工作单元,发送一个远程调度任务就会产生一个Span,Span是一个64位ID唯一标识的,Trace是用另外一个64位ID唯一标识的。Span还包含了其他信息,例如摘要,时间戳时间,Span的ID和进程ID。
- Trace:由一系列的Span组成的,呈树状结构。请求一个微服务系统的API接口,这个API接口需要调用多个微服务单元,调用每一个微服务单元都会产生一个新的Span,所有由这个请求产生的Span组成了这个Trace。
- Annotation:用于记录一个事件,一些核心注解用于定义一个请求的开始和结束,这些注解如下:
- cs-Client Sent:客户端发送一个请求,这个注解描述了Span的开始。
- sr-Server Received:服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳,便可得到网络传输的时间。
- ss-Server Sent:服务端发送响应,该注解表明请求处理的完成(当请求返回客户端),用ss的时间戳减去sr的时间戳,便可以得到服务器请求的时间。
- cr-Client Received:客户端接受响应,此时Span结束,如果cr的时间戳减去cs的时间戳,便可以得到整个请求所消耗的时间。
Zipkin Server
- Spring Cloud目前已经不支持单独构建Zipkin服务器,可以从https://zipkin.io/pages/quickstart下载Zipkin并且直接运行。
Tracing Data Persistence
- 通常使用ElasticSearch和Kibana对Tracing Log进行持久化和分析。
- 启动Zipkin时搭配一些customized jvm properties便可使Zipkin连接到Message Queue或者Elastic Search服务器。
Additional:
Elasticsearch
- Elasticsearch is a full-text, distributed NoSQL database. In other words, it uses documents rather than schema or tables. It’s a free, open source tool that allows for real-time searching and analyzing of your data.
- You can send data in the form of JSON documents to Elasticsearch using the API or ingestion tools such as Logstash and Amazon Kinesis Firehose. Elasticsearch automatically stores the original document and adds a searchable reference to the document in the cluster’s index. You can then search and retrieve the document using the Elasticsearch API. You can also use Kibana, an open-source visualization tool, with Elasticsearch to visualize your data and build interactive dashboards.
INFO [gateway-service,d102b1cce1e5427e,d102b1cce1e5422e,true]- gateway-service – Name of current Microservice,
- d102b1cce1e5427e – Trace ID,
- d102b1cce1e5422e – Span ID,
- true – If the information is sent to Zipkin.
11. Spring Boot Admin
- Spring Boot Admin是一个用于管理和监控一个或者多个Spring Boot程序。 Spring Boot Admin分为Server端和Client端,Client端可以通过Http向Server提供注册,也可以结合Spring Cloud的服务注册组件Eureka进行注册。
12. Spring Boot Security
- Spring Security采用”安全层”的概念,使每一层都尽可能的安全,连续的安全层防护可以达到全面的防护。Spring Security可以在Controller层,Service层,DAO层等以加注解的方式来保护应用程序的安全。Spring Security提供了细粒度的权限控制,可以精细到每一个API接口,每一个业务方法或者每一个操作数据库的DAO层的方法。
- Spring Security提供的是应用层协议的安全解决方案,一个系统的安全还需要考虑传输层和系统层的安全。
Reason for Using Spring Security
- 最重要的原因是Spring Security对环境的无依赖性,低代码耦合性。Spring Security提供了很多的module,module与module之间的耦合性低,module之间可以自由组合来实现特定需求的安全功能,具有较高的可定制性。总而言之,Spring Security具有很好的可复用性和可定制性。
- 在安全方面,主要有两个领域:
- Authentication:who are you. 可以是用户,设备或者其他系统。
- Authorization:what permission do you have。
Spring Boot Security and Spring Security
- Spring Security中主要有两个依赖:
- spring-security-web
- spring-security-config
- Spring Boot Security仅仅是对Spring Security进行了封装并且添加了Spring Boot起步依赖的特性。
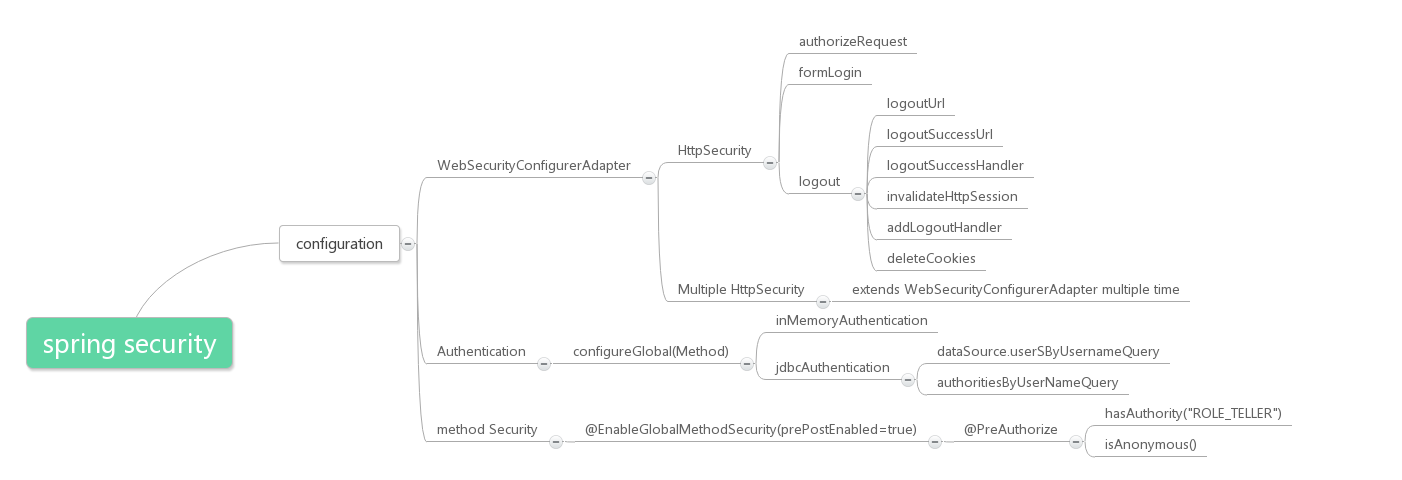
Spring Security Method Protect
- 通过对于继承
WebSecurityConfigurerAdapter类使用@EnableGlobalMethodSecurity(prePostEnabled = true)可以开启方法级别的保护。该注解有三个properties:prePostEnabled:@PreAuthorize和@PostAuthorize是否可用。secureEnabled:@Secured注解是否可用。jsr250Enabled:Spring Security对JSR-250的注解是否可用。
- 一般来说,只会用到
prePostEnabled,因为@PreAuthorize和@PostAuthorize注解更适合方法级别的安全控制,并且支持Spring EL表达式,适合Spring开发者。其中@PreAuthorize注解会在进入方法前进行权限验证,@PostAuthorize注解会在方法执行后再进行权限验证(应用场景很少)。- 常见的使用场景(在Method上使用):
@PreAuthorize("hasRole('ADMIN')")@PreAuthorize("hasAuthority('ROLE_ADMIN')")@PreAuthroize("hasAnyRole('ADMIN', 'USER')")@PreAuthorize("hasAnyAuthority('ROLE_ADMIN', 'ROLE_USER')")
- 常见的使用场景(在Method上使用):
- 对于Spring Security而言,它只控制方法,不论方法在哪个层级上。
13. Spring Cloud OAuth2
- OAuth2允许不同的客户端通过authentication和authorization的形式来访问被其保护起来的资源。在authentication和authorization的过程中,主要包含以下四种角色:
- 服务提供方 Authorization Server
- 资源持有者 Resource Owner
- 资源服务器 Resource Server
- 客户端 Client
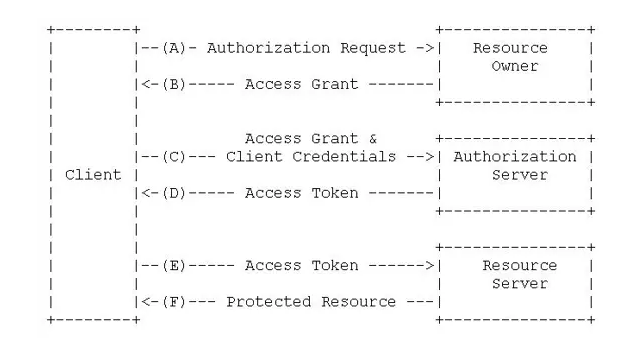
- OAuth2的Authentication的流程如下:
- 用户(Resource Owner)打开客户端,客户端询问用户授权。
- 用户同意授权。
- 客户端(Client)向授权服务器申请授权。
- 授权服务器对客户端进行认证,也包括用户信息的认证,认证成功后授权给予令牌。
- 客户端获取令牌后,携带令牌向资源服务器请求资源。
- 资源服务器确认令牌正确无误,向客户端释放资源。
- 最关键的步骤是用户如何向客户端授权,简而言之就是客户端如何获取token,授权存在四种模式:
- 授权码模式(authorization code): 功能最完整、流程最严密的授权模式
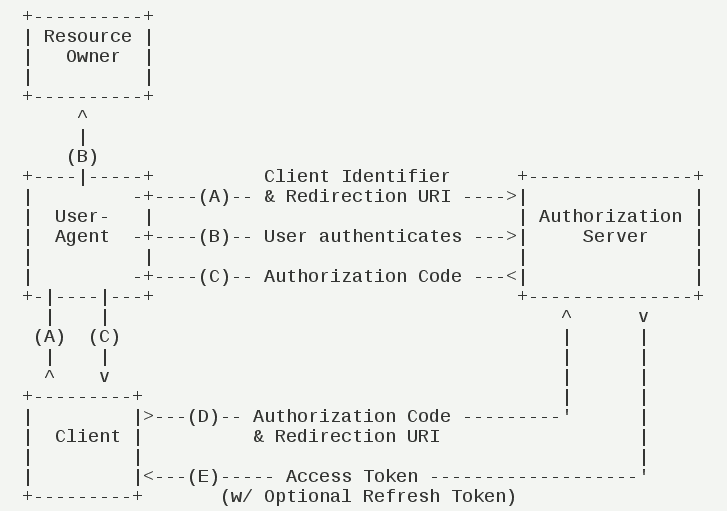
- (A)用户访问客户端,后者将前者导向认证服务器。
- (B)用户选择是否给予客户端授权。
- (C)假设用户给予授权,认证服务器将用户导向客户端事先指定的”重定向URI”(redirection URI),同时附上一个授权码。
- (D)客户端收到授权码,附上早先的”重定向URI”,向认证服务器申请令牌。这一步是在客户端的后台的服务器上完成的,对用户不可见。
- (E)认证服务器核对了授权码和重定向URI,确认无误后,向客户端发送访问令牌(access token)和更新令牌(refresh token)。
- 简化模式(implicit)
- 密码模式(resource owner password credentials)
- 客户端模式(client credentials)
- 授权码模式(authorization code): 功能最完整、流程最严密的授权模式
Spring OAuth2
- OAuth2 Protocol在Spring Resources中的实现为Spring OAuth2。Spring OAuth2分为两部分,分别是OAuth2 Provider和OAuth2 Client。
OAuth2 Provider
- OAuth2 Provider负责公开被OAuth2保护起来的资源。OAuth2 Provider需要配置代表Resource Owner的OAuth2 Client信息,被用户允许的客户端就可以访问被OAuth2保护的资源。
- OAuth2 Provider还必须为用户提供认证API接口。根据认证API接口,用户提供username&password等信息,来确认客户端是否可以被OAuth2 Provider授权。这样做的好处就是第三方客户端不需要获取用户的账号和密码,通过授权的方式就可以访问被OAuth2保护起来的资源。
- OAuth2 Provider的角色被分为Authorization Service和Resource Service,通常它们不在同一个服务中,可能一个Authorization Service对应多个Resource Service。
- Spring OAuth2需要配合Spring Security一起使用,所有的请求都是由Spring MVC控制器处理,并经过一系列的Spring Security过滤器。
- 通常Spring Security过滤器链中有以下两个endpoint,这两个endpoint是向Authorization Service获取验证和授权的。
- Authorization Endpoint:默认为oauth/authorize。
- Generate Token Endpoint:默认为oauth/token。
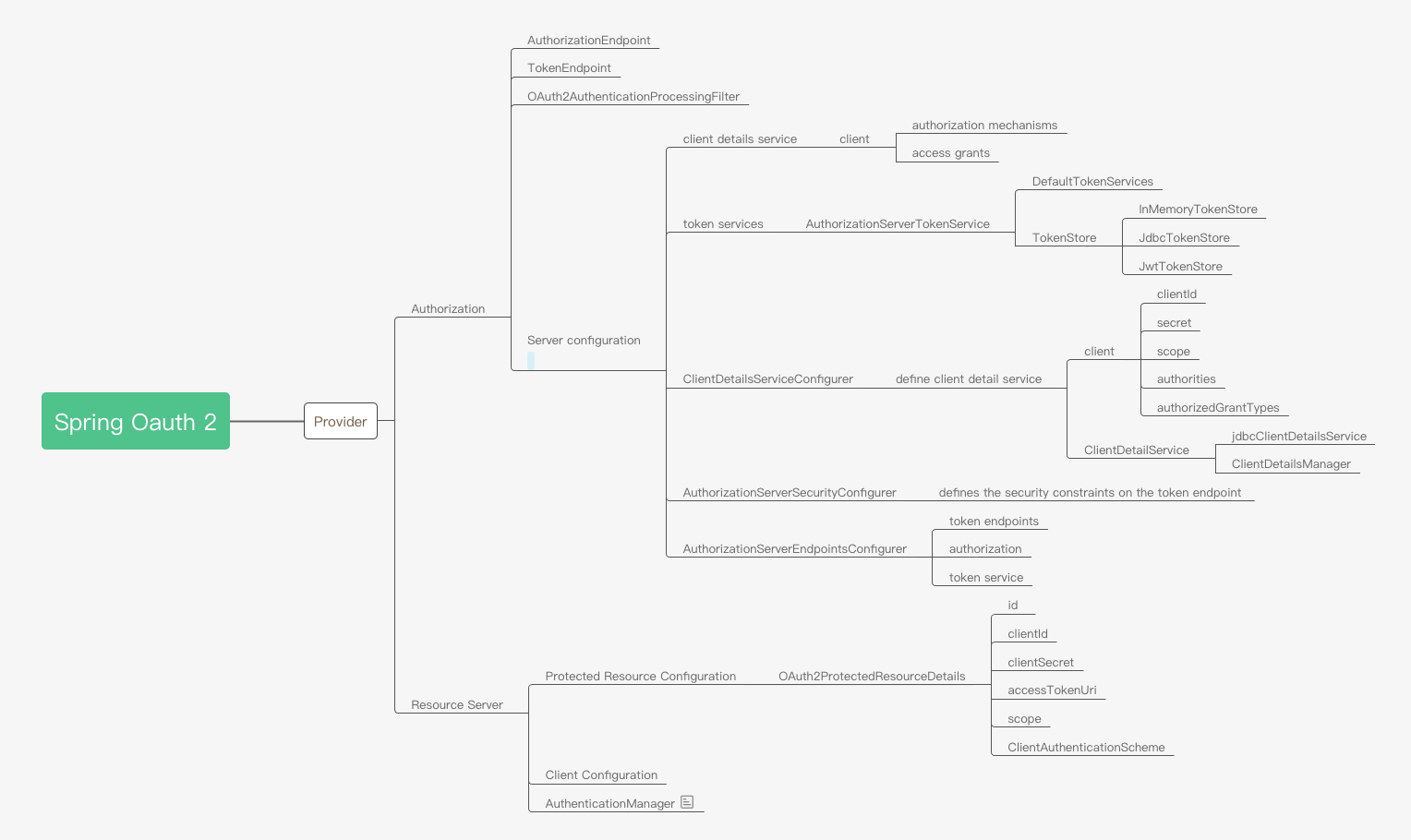
Authorization Server Config
- 在配置Authorization Server时,需要考虑client从用户获取访问令牌的授权类型。Authorization Server需要配置Client的详细信息和token service的实现。
- 在任何实现了
AuthorizationServerConfigurer接口的类上加@EnableAuthorizationServer注解,就可以开启Authorization Server的功能,其中以下三个config为必须实现。ClientDetailsServiceConfigurer:配置Client的信息。- clientId
- secret
- scope
- authorizedGrantTypes-认证类型
- authorities-权限信息
AuthorizationServerEndpointsConfigurer:配置授权token的endpoint和token service。- authenticationManager-密码认证
- userDetailsService-从数据库中获取用户信息
- authorizationCodeServices-配置验证码服务
- implicitGrantServices-配置管理implicit验证的信息
- tokenGranter-配置Token Granter
- tokenStore-Token的管理策略
- InMemoryTokenStore
- JdbcTokenStore
- JwtTokenStore
AuthorizationServerSecurityConfigurer:如果资源服务和授权服务是同一个服务器,则使用默认的配置即可。如果不在同一个服务器,则需要做一些额外设置。如果采用RemoteTokenServices(远程验证Token),资源服务器每次请求所携带的Token都需要从授权服务器做验证。这时需要配置/oauth/validateToken节点。